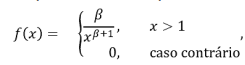1
Q1091304
1 > x <- c(2,1,3,5,6)
2 > y <- matrix(1:25, nrow = 5)
Com base no código precedente, escrito em R, em que os números à esquerda do sinal “>” indicam o número da linha do código, julgue o item a seguir, assumindo que a tecla Enter foi pressionada após cada linha de comando do código.
O comando x == 1:5 produzirá uma lista de valores, dos quais apenas um é TRUE.