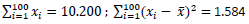1
Q1075702
Acerca de técnicas utilizadas na ciência de dados, julgue o item a seguir.
O K-means exige a definição do número de clusters como parâmetro de entrada e tem um desempenho eficiente em grandes conjuntos de dados, mas é sensível a outliers e só funciona bem para clusters esféricos e de densidade semelhante.